Intro
몇 번이고 기술 면접에서 털리다보니 좀 쪽팔리기도 하고 형형하게 알고 있지 못한 것을 말로 설명하려니 항상 어려운 것 같아서 글로라도 정리해보려고 시작하는 기술 면접 대비 CS 포스팅이다. 공부를 어디서부터 어떻게 시작하면 좋을지 감이 잡히지 않아 차일피일 미루던 중 유튜브에서 개발자 장고라는 분의 면접 대비 영상을 보게되었고 (알고리즘 땡큐?) 영상을 보고 정리하는 것부터 시작해보려고 한다. 정리하다보면 더 궁금한게 생길 수도 있고 그러면 가닥이 잡히겠지!?
운영체제
운영체제란 시스템의 자원과 동작을 관리하는 소프트웨어입니다. 운영체제는 프로세스, 저장장치, 네트워킹, 사용자, 하드웨어 등을 관리합니다.
실행 파일 생성 과정
소스코드는 빌드를 통해 실행 파일이 됩니다. 실행 파일은 CPU가 읽을 수 있는 기계어인 이진 코드로 되어있습니다. 빌드는 3가지 방식이 있는데, Compile 방식, Interpreted 방식, Hybrid 방식입니다.
[Compile 방식]
컴파일 방식은 컴파일 과정을 거쳐 소스 코드를 한 번에 실행파일로 만들어줍니다. C, C++, Go와 같은 컴파일 랭귀지가 이런 방식으로 빌드되며, 전처리(ex: #include) -> 컴파일(고급어를 어셈블리어로) -> 어셈블(어셈블리어를 기계어로) -> 링크(.exe 로) 4단계를 거쳐 실행파일이 됩니다. 컴파일 방식의 장점은 한 번에 모두 실행 파일로 만들기 때문에 만들어진 실행 파일의 처리 속도가 빠릅니다. 단점은 프로그램 수정이 필요한 경우 수정 후 다시 전체 소스코드를 빌드하는 과정을 거치기 때문에 대규모 프로그램이라면 생산성이 떨어질 수 있습니다. 그리고 운영체제에 의존적입니다. (ex: 프로그램을 설치할 때 맥용, 윈도우 64 등 다르게 설치 필요)
[Interpreted 방식]
인터프리티드 타입은 소스코드를 한 번에 실행파일로 번역 후 실행하는 것이 아닌 명령 단위로 해석하여 즉시 실행하는 것입니다. 컴파일 타입이 목적 파일을 만드는 것과 달리 인터프리티드 타입은 목적 파일 없이 바로 실행합니다. 대표적인 언어로 Phython, JavaScript, Ruby가 있습니다. 소스 코드 명령마다 기계어로 번역하여 바로 실행하는 것입니다. 인터프리터만 있으면 실행되기 때문에 운영 체제에 독립적이고, 컴파일 과정 없이 인터프리터를 통해 바로 결과를 볼 수 있어 프로그램 수정에 유리하고 개발 속도가 빨라집니다. 하지만 이미 다 빌드된 것을 실행하는 컴파일 방식에 비해 실행 속도가 느리고, 보안에 취약할 수 있습니다.
[Hybrid 방식]
컴파일 타입과 인터프리티드 타입을 혼합한 것입니다. 바이트 코드 언어라고도 하며, 대표적인 언어로 Java가 있습니다. 하이브리드 타입은 고급 언어로 작성된 소스코드를 가상머신이 이해할 수 있는 중간 언어인 바이트 코드로 변환합니다. (.class) 그리고 VM(Virtual Machine)을 통해 바이트 코드를 기계어로 바꿉니다. 그리고 각 운영체제에 그에 맞는 가상 머신을 만들고 기계어로 바꿉니다. 미리 소스코드를 바이트 코드로 컴파일하는 컴파일 타입의 특성 + 인터프리터 역할을 하는 VM을 통해 기계어로 바꿔 운영체제에 독립적이므로 인터프리티드 타입의 특성을 모두 갖춘것입니다. 때문에 속도가 빠르고 운영체제에 독립적입니다. 다만 실행이 가상 머신에서 이루어지기 때문에 완전한 컴파일 타입 언어처럼 하드웨어를 직접 컨트롤 하는 것은 불가능합니다.
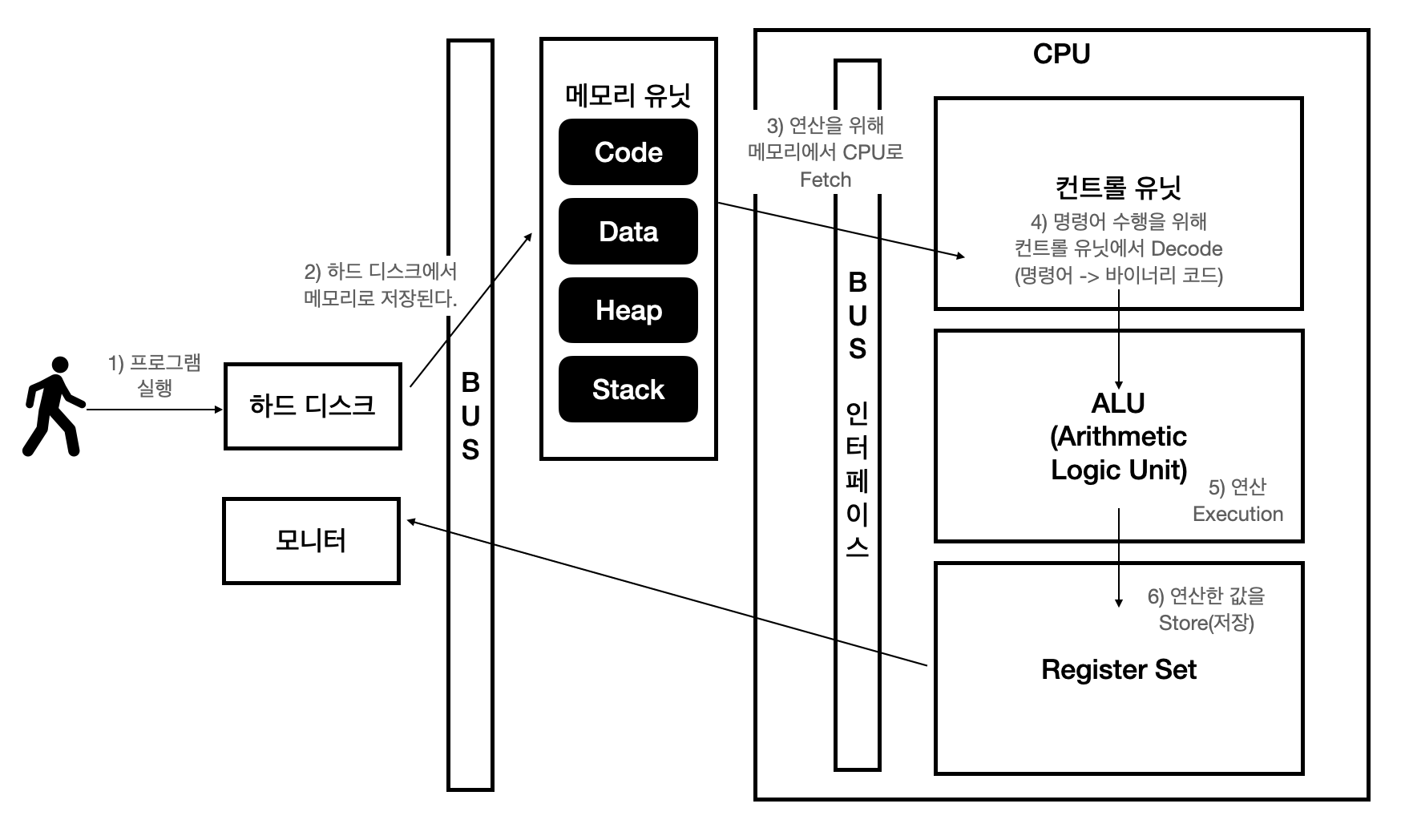
프로그램 실행 과정
컴퓨터는 Stored Program Concept로 폰노이만 아키텍처라고 부르기도 합니다.
1. 프로그램을 실행한다.
2. 하드디스크에서 메모리로 저장한다.
3. 연산을 위해 메모리에서 CPU로 Fetch 한다.
4. 명령어 수행을 위해 컨트롤 유닛에서 바이너리 코드로 Decode 한다.
5. ALU(Arithmetic/Logic 유닛)에서 연산한다.
6. 연산한 값을 레지스터셋에 저장한다.
캐시
캐시란 자주 사용하는 데이터나 값을 미리 복사해 놓는 임시 장소 입니다. 캐시는 저장 공간이 작고 비용이 비싸지만 빠른 성능을 제공한다. Cache는 반복적으로 데이터를 불러오는 경우에 지속적으로 DBMS 또는 서버에 요청하는 것이 아니라 Memory에 데이터를 저장하였다가 쓰는 것이다. DBMS 부하를 줄일 수 있고 성능을 높일 수 있습니다. 원하는 데이터가 캐시에 존재하여 해당 데이터를 반환하는 것을 'Cache Hit'라고 하며, 원하는 데이터가 캐시에 없어 DBMS/서버에 요청하는 것을 'Cache Miss'라고 한다. 캐시는 저장 공간이 작기 때문에 지속적으로 캐시 미스가 발생한다면 캐시 전략을 변경하는 것이 좋습니다. (관련: 롱테일 법칙 - 20% 요구가 시스템 리소스 대부분을 사용한다.)
[Local Cache]
- 로컬 장비 내에서만 사용하는 캐시로 로컬 장비의 리소스를 이용한다.
- 로컬에서만 작동하기 때문에 속도가 빠르지만, 다른 서버와 데이터 공유가 어렵다.
[Global Cache]
- 분산된 서버에 데이터를 저장하고 조회할 수 있다.
- 네트워크를 통해 데이터를 가져오므로 로컬 캐시에 비해 느리지만, 서버 간 데이터 공유가 쉽다.
메모리 구조
메모리 공간은 코드 영역, 데이터 영역, 힙 영역, 스택 영역 4가지로 구분됩니다. 코드 영역은 소스 코드가 있는 공간이고, 데이터 영역은 전역 변수, 정적 변수가 할당되는 부분입니다. 힙 영역은 런 타임에 데이터가 동적으로 할당되는 공간으로 사용자가 관리하는 공간입니다. 마지막으로 스택은 함수의 호출 정보, 지역 변수, 매개 변수가 저장되는 곳입니다.

전역 변수 VS 정적 변수 VS 지역 변수 VS 매개 변수
[전역 변수]
global variable. 프로그램 전체의 어느 지역에서든 참조할 수 있는 변수입니다. 전처리기 밑에 선언하며, 반드시 상수로 초기화 해야합니다. 초기화를 하지 않는 경우 디폴트값 0으로 자동 초기화 됩니다. 프로그램이 시작될 때 메모리에 생성되고 프로그램이 종료될 때 메모리에서 소멸 됩니다. 초기화 하는 경우 메모리의 Data 영역에 할당되고 초기화를 하지 않는 경우 BSS 영역에 할당 됩니다.
[정적 변수]
static variable. 프로그램이 시작될 때 메모리에 생성되어 프로그램이 종료될 때 소멸되는 변수 입니다. 초기화 할 때 반드시 상수로 초기화 해야하며 초기값을 지정하지 않으면 0으로 자동 초기화 됩니다. 전역 변수와 다른점은 정적 변수는 프로그램이 시작될 때 딱 한 번만 초기화가 진행된다는 것입니다. 정적 변수는 함수의 매개 변수로는 사용할 수 없습니다. 정적 변수는 사용 범위에 따라 정적 지역 변수, 정적 전역 변수로 나뉩니다. 정적 지역 변수는 중괄호 내부에서만 사용 할 수 있고, 한 번 초기화되면 이후에 함수가 다시 호출될 때는 초기화를 하지 않습니다. 정적 전역 변수는 선언된 소스 파일에서만 사용할 수 있고 외부에서는 쓸 수 없습니다. 기화 하는 경우 메모리의 Data 영역에 할당되고 초기화를 하지 않는 경우 BSS 영역에 할당 됩니다.
[지역 변수]
local variable. 중괄호 내부나 함수의 매개변수(parameter)에서 사용되는 변수입니다. 선언된 함수 안에서만 접근이 가능하며, 함수를 벗어나면 메모리 공간이 소멸됩니다. 지역변수는 초기화 하지 않으면 컴파일 에러가 나거나 쓰레기값이 저장됩니다. 지역변수는 함수 내부에서만 쓰이는 변수로 stack 영역에 할당됩니다.
[매개 변수]
parameter. 함수를 호출할 때 인수로 전달되는 값을 함수 내부에서 사용할 수 있게 해주는 변수입니다. 매개변수의 전달 방식에는 값 전달 방식, 참조 전달 방식이 있습니다. 값 전달 방식(passing by value)은 인수를 함수에 전달하면 새롭게 생성된 매개변수에 전달 받은 값을 복사하여 저장하는 방식입니다. 즉, 매개변수에 저장한 값은 복사본으로 함수 안에서 변경하여도 함수 밖의 원본 데이터는 영향을 받지 않습니다. 참조 전달(passing by reference) 방식은 인수로 전달 받은 원본 데이터에 대한 참조 변수를 매개 변수에 전달하는 것입니다. 따라서 원본 데이터를 그대로 참조하게 되어 함수 내부에서 값을 변경하면 함수 밖의 원본 데이터 역시 바뀌게 됩니다.
Stack VS Heap
[Stack]
함수를 호출 할 때 매개 변수나 지역 변수 등이 주로 스택 메모리에 할당됩니다. 스택 메모리는 컴파일 시 이미 결정되며 함수가 호출될 때마다 해당 변수는 스택에 할당된 메모리를 가져옵니다. 함수 호출이 끝나면 변수에 대한 메모리 할당이 해제됩니다. 모든 것이 컴파일러에서 미리 정의된 류틴을 사용하기 때문에 메모리 할당이나 해제를 신경쓰지 않아도 됩니다. 메모리 할당 및 해제 속도가 힙 메모리에 비해 빠르고 안던하다는 장점이 있지만 힙 영역에 비해 저장 공간이 적어 StackOverFlowError 등이 발생할 수도 있습니다.
[Heap]
힙 영역 메모리는 런타임(명령을 실행하는 동안)에 할당됩니다. 객체를 만들면 힙 공간에 생성되고 이러한 객체의 참조 정보가 스택 메모리에 저장됩니다. 힙 메모리에 할당된 데이터는 모든 스레드에서 액세스가 가능하기 때문에 스택 영역보다 안전하지 않습니다. 스택 영역에 비해 메모리 크기가 크지만, 프로그래머가 직접 할당/해제 해주어야 하며 제 때에 메모리 를 해제하지 않으면 메모리 누수의 가능성도 있습니다. 자바의 경우 가비지 컬렉터가 이를 대신합니다. 힙 메모리 할당은 세 가지 범주가 있으며,이 범주는 가비지 컬렉션에 저장할 객체의 우선순위를 정하는데 도움이 됩니다.
- Yong Generation: 모든 새로운 데이터(객체)가 만들어지는 메모리 부분이며, 이 메모리가 완전히 채워지면 나머지 데이터는 Garbage Collection에 저장됩니다.
- Old or Tenured Generation: 자주 사용하지 않거나 전혀 사용하지 않는 오래된 데이터 객체가 배치되는 힙 메모리의 일부입니다.
- 영구 생성: 런타임 클래스 및 애플리케이션 메서드에 대한 JVM의 메타데이터를 포함하는 힙 메모리의 부분입니다.
GC 과정
[Minor GC]
1. 최초의 객체가 Heap - Young Generation의 Eden에 생성된다.
2. Young Generation Eden 공간이 다 차면(Full) Minor GC 발생(사용되지 않거나 참조하고 있지 않는 객체는 삭제하고 나머지 객체를 이동) -> 살아남은 객체는 Survivor-From으로 이동한다.
3. 다시 Eden이 GC가 발생하면 From -> To로 이동한다. (포인터를 변경해주는 것)
4. 이 과정의 반복 이후에도 객체가 여전히 살아있다면 Old Generation으로 이동한다.
Minor GC는 매우 빠르고 효율적이며 JVM Thread Processing을 멈추게 하는 등의 부작용도 없습니다.
[Major GC]
Young Generation이 다 차면 Major GC가 수행됩니다.
5. Major GC의 Garbage Collection은 객체들이 살아있는지 여부를 파악하기 위해 모든 Thread의 실행을 잠시 멈추고 살아있는 객체를 표시하고, 사용하지 않는 객체를 제거하여 heap을 정리한다. (=Mark and Sweep) 이 작업은 CPU에 부하를 가하며 마이너 GC에 비해 10배 이상의 시간을 사용하기 때문에 성능에 좋지 않다.
-> 때문에 생명 주기가 짧은 젊은 객체는 Young Generation에서 제거되게 하고 오래된 객체는 Old Generation에 상주시켜 Minor GC만으로 heap 유지가 가능하도록 유도하는 것이 좋습니다.. 이를 위해서는 Young Generation은 전체 Heap의 1/2보다 약간 작게, Survivor Space는 영 제너레이션의 1/8 정도가 적당합니다.
GC를 수행할 때 모든 스레드 작업을 멈추기 때문에 GC관리는 시스템 안정성에 큰 변수로 작용합니다.
Visibility(가시성) & Atomicity(원자성)
멀티 스레드 환경에서 공유 자원을 사용할 때는 가시성과 원자성을 고려해야 합니다. 가시성이란 멀티 스레드에서 공유 자원에 대해서 모두 같은 상태를 바라보고 있는 것입니다. CPU의 캐시를 사용하지 않고 메인 메모리에서 바로 가져오도록 하는 volatile 선언을 통해 가시성을 확보할 수 있습니다. 원자성이란 멀티 스레드에서 공유 자원에 대한 수정이 모두 반영 되도록 하는 것입니다. synchronized라는 키워드를 사용해 동기화하여 한 번에 하나의 스레드만 공유 자원에 접근을 하도록 함으로써 원자성을 확보할 수 있습니다.
프로세스 & 스레드
프로세스는 실행 중인 프로그램이고, 스레드는 프로세스 안의 실행 단위 입니다. 유튜브를 예로 들면, 유튜브가 프로그램이고, 유튜브 프로그램 안에 좋아요나 스트리밍, 댓글 달기 등이 각각의 스레드 입니다. 프로세스는 각각의 독립된 메모리 영역을 할당 받습니다. 기본적으로 프로세스 당 최소 1개의 스레드(메인 스레드)를 가지고 있습니다. 서로 다른 프로세스는 서로의 메모리에 직접 접근할 수 없습니다. 반면에 스레드는 프로세스 내에서 각각 stack(함수 호출 정보, 지역 변수, 매개 변수가 할당되는 공간) 영역만 따로 할당 받고, Code, Dta, Heap 영역은 공유 합니다.
CPU 스케줄러
준비 큐에 있는 프로세스에 대해 CPU를 할당하는 방법입니다. 스케줄링 방식은 크게 3가지로 비선점 스케줄링, 선점 스케줄링, 우선순위 스케줄링이 있습니다. 비선점 스케줄링에는 먼저 온 순서대로 처리하는 FCFS와 CPU 사용 시간이 짧은 순으로 처리하는 SJF가 있습니다. 선점 스케줄링에는 잔여 시간이 짧은 프로세스가 있는 경우 먼저 실행하는 SRT와 공평하게 돌아가며 처리하는 RR이 있습니다. 우선순위 스케줄링은 우선순위를 설정하여 우선순위가 높은 순으로 처리하는 방식입니다.
[비선점 스케줄링]
- FCFS(First Come First Served): 먼저 온 프로세스부터 처리
- SJF(Shortest Job First): CPU 사용 시간(Burst Time)이 짧은 프로세스부터 처리
[선점 스케줄링]
- SRT(Shortest Remaining Time): 잔여 시간이 짧은 프로세스부터 처리
- RR(Round Robin): Time Slice 만큼 공평하게 돌아가며 처리(각 수행 시간=Time Slice 이 너무 길면 FCFS와 큰 차이가 없다. 너무 짧으면 비용이 너무 많이 든다.)
[우선 순위 스케줄링]
- 우선순위가 높은 프로세스를 먼저 처리
가상 메모리
메모리 크기에는 한계가 있기 때문에 프로세스 중 사용하는 부분만 메모리에 올리고 나머지는 디스크에 보관하는 것입니다. (페이지 테이블 이용)
데드락
데드락은 프로세스가 자원을 얻지 못해 다음 작업을 하지 못하는 상태입니다. 데드락은 네 가지 조건이 동시에 충족되어야 발생하며, 4가지 조건은 상호 배제, 점유 대기, 비선점, 순환 대기 입니다.
'기타 CS' 카테고리의 다른 글
| 기술 면접 준비 - 웹 브라우저 작동 방식 (0) | 2023.02.22 |
|---|---|
| 기술면접 준비 - 데이터베이스(2) (0) | 2023.02.22 |
| 기술 면접 준비 - 데이터베이스(1) (0) | 2023.02.22 |
| 기술 면접 준비 - 네트워크 (0) | 2023.02.21 |
| 마이크로 서비스 패턴(2020, 크리스리처드슨) (0) | 2023.01.30 |

